کاربرد تحلیل داده های شبکه ای محتوای شبکه های اجتماعی موبایلی، به منظور سنجش ویژگی های شخصیتی، توان
نویسنده و مسول مقاله: محمد حسین ضرغامی (دکتری سنجش و اندازه گیری)
یکی از مهمترین موانع جدی تصمیم گیری برای کسانی که لازم است دست به قضاوت و ارزشیابی بزنند- مثلا روانشناسان، مشاوران، مدیران و غیره- اطلاعاتی است که عموما از طریق روش های خودگزارش دهی[1] جمع آوری می شوند. روش های خودگزارش دهی عمدتا از طریق مصاحبه، پرسشنامه، چک لیست و یا مشاهده صورت می پذیرند. به نظر می رسد استفاده از داده های فیزیولوژیکی مانند نتایج بدست آمده از EEG، MRI، FMRI، Eye tracking و ... بتواند بر بعضی از مشکلات ناشی از روش های خودگزارش دهی فائق آید. با این وجود استفاده از این روش ها علاوه بر این که نیازمند ابزار و هزینه های خاص است، میزان موفقیت آنها در بیشتر مقالات گزارش شده، تفاوت معناداری با نتایج بدست آمده از روش های خودگزارش دهی ندارد. شایان ذکر است که مساله ی اعتباریابی این روش ها، به همان اندازه ی روش های خودگزارشی سوال برانگیز است.
ظهور شبکه های اجتماعی آنلاین[2] یکی از حوزه های پر هیجان دهه ی اخیر مخصوصا در روابط اجتماعی به شمار می رود. شبکه های اجتماعی موبایل مانند وایبر[3]، تلگرام[4]، واتس اپ[5]، تانگو و سایر شبکه های اجتماعی در بین کاربران به سرعت محبوب شده اند. چنین شبکه هایی به لحاظ محتوایی فوق العاده غنی اند و حجم بسیار بالایی از محتوا و داده های ارتباطی را در بر می گیرند که برای دستیابی به اهداف مختلف مورد تحلیل قرار می گیرند. امروزه داده های چنین شبکه هایی به عنوان طلای سیاه در نظر گرفته می شوند(هان و کامبر، 2011).

ساختار اطلاعات[6] موجود در شبکه های اجتماعی با مولفه های نظریه گراف[7] همخوان است. دو مولفه ی اساسی تئوری گراف، رآس[8] و یال[9] است. راس یا گره در شبکه های اجتماعی متون، تصاویر و سایر چند رسانهایها است و یال یا ارتباط بین رئوس، ویژگی یا چیزی است که به عنوان رابط بین گره ها در نظر گرفته می شود. غنای چنین شبکه هایی فرصت های بی سابقه ای را برای تحلیلگران داده در حوزه های مختلف، از فلسفه تا علم[10] فراهم می آورد.
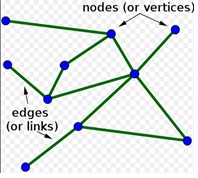
شبکه اجتماعی می تواند بر اساس اهداف مختلف به شیوه های گوناگون تعریف شود. به عنوان مثال یک گروه دوستی می تواند به عنوان یک شبکه ی اجتماعی مقصود اصلی مطالعه باشد. البته پر واضح است که اگر صرف ارتباط، مورد نظر باشد؛ هر گروه دوستی در شبکه های اجتماعی موبایل، در برگیرنده ی تمام افراد جهان می شود که برنامه ی مربوط به آن شبکه را روی موبایل خود نصب کرده و از آن استفاده می کند. از این منظر شما خواننده عضو تمام گروههای دوستی موجود در جهان می باشید و در صورت فائق آمدن بر موانع سخت افزاری و نرم افزاری می توانید ارتباط دلخواهتان را برقرار نمایید. به لحاظ نظری و تجربی این موضوع سال ها قبل از پیدایش موبایل و اینترنت توسط میلگرام در مقاله ای با عنوان جهان کوچک[11] مطرح و به لحاظ تجربی ثابت شده است(https://en.wikipedia.org/wiki/Small-world_experiment). بنابراین تعیین حد و مرز و تعریف شبکه ی مورد مطالعه بسیار اهمیت دارد و این مهم، از طریق الگوریتم های مبتنی بر مدل های آماری گراف و داده های شبکه ای[12] امکان پذیر است.
شخصيت را شايد بتوان اساسی ترين موضوع علم روان شناسی دانست؛ زيرا محور اساسی بحث در زمينه هايی مانند يادگيری، انگيزش، ادراک، تفکر، عواطف و احساسات، هوش و مواردی از اين قبيل است. از طرف ديگــر، در مطالعــه ی بيماری هــای روانی کنشی، مانند انواع ســايکوزهای کنشی، اختلالات شخصيت و منش، تمام نوروزها، رفتارهای ضد اجتماعــی و ضد اخلاقی، اعتياد و انحراف ها، شخصيت نقش محوری و اساسی دارد. در رابطه با جايگاه و اهميت شخصيت در روان شناسی، گفته شده است که شخصيت مانند ديگی است که همه ی مخلفات روان شناسی در آن پخته می شود (شاملو، ۱۳۷۷). از این رو سنجش ویژگی های شخصیتی و توانمندی های هوشی در حوزه ی منابع انسانی[13] و روانشناسی غیر قابل انکار است به طوری که بخش عظیمی از فعالیت ها و تلاش های روانسنجان در گذشته و در زمان حال را به خود اختصاص داده است.

تشخیص بالینی مهمترین و پایه ای ترین گام درمان به شمار می رود که توسط روانشناسان و روانپزشکان و عمدتا بر اساس نشانگان بالینی مراجع صورت می پذیرد. با وجود آموزش های مختلفی که این متخصصان دریافت می کنند، تشخیص های بالینی می تواند از سوگیری های فردی[14]، فرافکنی شخصی[15]، اثر معیار سرایت، اثر هاله ای[16]، نقاب های اجتماعی[17] و سایر عوامل مختل کننده که ناشی از ارتباط بین فردی[18] است؛ متاثر شود. علاوه بر این فرد می تواند در خود اظهاری به خاطر مجموعه ی کلانی از عوامل فردی و اجتماعی در روند تشخیص و درمان اختلال ایجاد نماید. در کنار تجارب و پیشینه ی مراجع و درمانگر، کلیه ی مولفه های فضا-زمان[19] و تعاملات بین آنها نقش تعیین کننده ای در فرآیند تشخیص، درمان و درمان پذیری دارد.
به کارگیری و استفاده از شیوه های سنجش غیر مستقیم[20] در تشخیص بیماری های روانی و یا برآورد ویژگی های شخصیتی افراد بسیار ضروری است. استفاده از روش های کشف دانش[21] مبتنی بر شبکه های اجتماعی (مانند شبکه های اجتماعی موبایل) می تواند در خدمت کسانی باشد که هدف آنها سنجش ویژگی های شخصیتی، توانمندی های هوشی و تشخیص بیماری های روانی است. خود ابرازگری افراد در این روش ها نسبت به موارد گفته شده بیشتر است، موانع اجتماعی به حداقل رسیده و شبکه ی ارتباطی فرد، امکان اعتباریابی تشخیص ها را فراهم می آورد. بنابراین از نگاه درمانی علاوه بر فرد، شبکه ی بسیار وسیعی از جهان ارتباطی وی و دیتای قابل توجهی از محتوای کلام در قالب نشانه –متن و تصویر و سایر ابزار چند رسانه ای- در دسترس است که می تواند شخصیت، توانمندی های شناختی و غربالگری روانی را به صورت غیر مستقیم سنجش نماید و درمان را به لحاظ ساختاری، به صورت همزمان، فردی و گروهی نماید.
- شاملو، سعید، «مکتب ها و نظریه ها در روانشناسی شخصیّت»، تهران، رشد، انتشارات رشد، 1390.
Han, J., Kamber, M., & Pei, J. (2011). Data mining: concepts and techniques: concepts and techniques. Elsevier.
[1]. Self-report
[2]. Online social networks
[3]. viber
[4]. telegram
[5]. What’s up
[6]. Information structure
[7]. Graph theory
[8]. node
[9]. edge
[10]. science
[11]. the small world
[13]. Human Rescores
[14]. Individual biases
[15]. Personal projection
[16]. Halo effect
[17]. Social persona
[18]. Intra individual
[19]. time-space components
[20]. Indirect assessment
[21]. Knowledge discovery
 به نام یزدان پاک
به نام یزدان پاک